云存储的黑暗面:元数据保障
本文主旨并非阐述一个可用的架构设计,而是展示出对象存储的元数据保障中将会遇到的问题。问题往往比答案更重要。多数问题只要认识清楚,解决并非难事。但需要注意的是,没有哪个问题存在十全十美的彻底解决方案。我们所采取的策略更多的是将一个关键性问题转化成另一个次要和易于处理的问题,或者将一个问题发生的可能性尽可能降低。很多问题是无法彻底解决的,我们的现实目标是将其发生的概率下降到业务可接受的范围。因此,希望大家能够更多地关注和发掘所存在的问题,而不是紧盯方案和设计。我们相信,认清了问题之后,找到解决办法并非难事。
在开始讨论元数据保障的问题之前,我们先要牢牢记住一句话:“任何事物都会出错。”这个真理时时刻刻在发挥着惊人的作用。
元数据
元数据系统的好坏关系到整个对象存储系统的可靠性、可用性和一致性,并且会影响到性能。因此,元数据部分是对象存储系统的核心,也是架构和保障的重中之重。
元数据最基本的作用在于数据对象的定位。对象存储的任务是保存用户提交的数据对象,并以用户指定的名称(Key)对其标识。用户如需获取一个数据对象,要向对象存储系统提交Key,存储系统便会根据Key找到相应的数据对象,然后反馈给用户。存储系统根据Key找到数据对象存放位置的过程,便是依托元数据完成的。图1是元数据方案架构图。
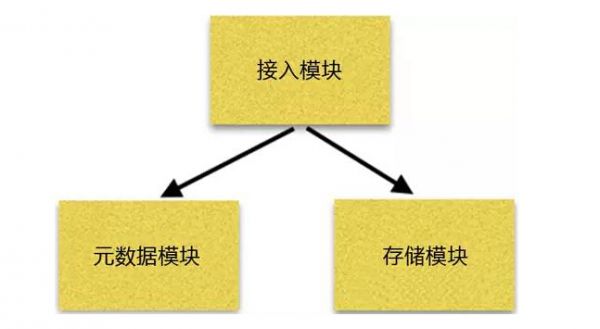
元数据的核心内容是Key=>Pos(存储位置)的映射,本质上是一个Map。此外,元数据还承载了数据对象归属(容器和用户)、大小、校验值等元信息,用于记账、校对、修复和分析等辅助操作。
说到这里,大家或许会有疑问:现今的存储系统都流行去中心化,设法去掉元数据,为何还要谈元数据的保障?原因其实很简单,当今各种去中心化的存储设计,在云存储中并不适用。其中原因颇为繁复,已超出本文范畴,这里只做简单说明。
去中心化的方案利用算法确定数据对象的位置。最常见的算法是一致性哈希。这些方案的问题在于,如果仅考虑数据对象的存取,逻辑很简单,实现上也简单。但如果考虑到可靠性、可用性、一致性,以及运维,就会变得复杂。
数据对象的存储副本总会损坏和丢失。一旦丢失,需要尽快修复。最极端的情况是某一磁盘失效,进而造成大量的数据副本需要修复。去中心化方案将数据对象的副本同磁盘一一对应起来,结果就是修复的数据只能灌入一块磁盘。单块磁盘的吞吐能力有限,从而造成一块磁盘的数据需要近一天的时间方能修复。而在大型存储系统中,这段时间内可能会有更多的磁盘发生损坏,因而可能造成数据的丢失。
同样因为数据对象与服务器和磁盘绑定,一旦一台服务器下线,便会降低相应对象的存取可用性。有些方案临时将数据对象映射到其他服务器,从而提高可用性,但临时状态的管理、其间的异常处理等问题的复杂性远远超出了去中心化所带来的便利。
当存储系统扩容时,去中心化方案需要在服务器之间迁移大量的数据,以求各磁盘的可用容量达到平衡。迁移规模随扩容规模增大而增加。迁移过程消耗系统资源,并且存在中间状态,使得数据存取逻辑复杂化。而且漫长的迁移过程中一旦发生异常,其处理过程相当繁复。
在一致性方面,去中心化方案碍于副本数较少,在某些特定情况下会造成一致性问题,而且难以修复。关于这一点,后面会具体论述。
对于list操作、数据校验、记账等辅助操作,各种去中心化的方案都很不友好。因为数据量庞大,无法通过遍历所有数据计算用量、分析统计。因此,一些去中心化方案会设置数据对象和用户的关联数据库,以方便使用量计算。这些数据库实际上就是一种元数据库,同样面临着元数据保障的问题。
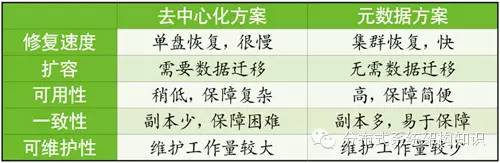
去中心化方案的诸多问题并非无法解决,总能找到合适的方法应对。但其实这只是将压力转移到运维阶段,使得运维成为瓶颈。我们说存储系统是“三分研发,七分运维”,运维是重中之重,无论从设计还是研发角度,都应当以方便运维,减少运维压力为先。表1中对比了去中心化方案和元数据方案。
元数据的特性
让我们回到元数据上来。元数据相对于数据对象本身,总量较少。根据统计,元数据和数据对象的大小之比大体在1:100到1:10000之间,具体的比率,取决于数据对象的平均大小。因此,元数据相比数据对象本身更加容易操作和处理。
当用户索取数据对象时,存储系统需要检索元数据库,找到相应的元数据条目,获得存储信息后,进行读取。因此,元数据的操作是查询操作,也就是数据库操作。正因为元数据的量较少,并且都是结构化数据,使得这种检索得以方便地实现。
即便如此,当存储量达到几十PB级别时,元数据的数据量也将达到几十上百TB的级别。这已远超出单台服务器的存储能力。因此,元数据库天生便是一个分布式集群。在分布式数据库集群中,很难维持复杂的数据结构,特别是在可靠性、可用性、一致性,以及性能的约束下,同时满足这些要求是极难做到的。在动辄数以PB计的云存储系统中,只得维持最简单的对象存储形态,这也就是大型的云存储系统不支持文件系统的原因。
元数据的重要性在于它是整个数据存储的基准:整个系统拥有哪些数据对象,归属哪些容器、哪些用户。一个数据对象,元数据说有,就有了;元数据说没有,就没有了。所以,元数据的可靠性代表着存储系统的可靠性。数据校验、空间回收等操作都依赖于元数据。元数据一旦有所差错,必然造成整个数据存储的错失和混乱。
同时,几乎所有操作都需要操作元数据,或读取,或写入,是存储系统的关键路径。如果元数据系统下线,那么整个存储系统就会宕机。因此,元数据部分的可用性决定了存储系统的可用性。
性能方面,几乎所有的操作都涉及到元数据,整个元数据系统的访问压力远远超过存储系统。因而,元数据的性能决定了存储系统的整体响应。
元数据的一致性也决定了存储系统的一致性。一致性决定了用户在不同时间对同一个对象访问是否得到同样的结果。当一致性发生问题时,用户在不同的时间可能获得某个对象的不同版本,甚至无法获得有效的对象。这些违背用户预期的情况往往造成用户业务逻辑的混乱,引发不可预期的结果。而在某些特定的情况下,一致性的错乱会增加数据丢失的可能性。
作为存储系统的枢纽,元数据占到整个系统大部分的维护工作量。元数据系统可维护性上的提升对于整体的运维有莫大的帮助。
元数据保障的真正困难在于上述这些特性的平衡和协调。这些特性之间有时会相互补充,但更多的时候会相互矛盾和冲突。试图解决其中一个方面的问题,可能导致其他方面受到损害。解决问题的过程充满了大量的折中手段。
接下来具体说一说云存储元数据保障所面临的问题和一般应对手段。