腾讯CSIG:腾讯优图实验室AI手语识别研究白皮书
前言
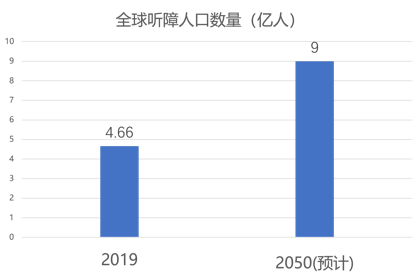
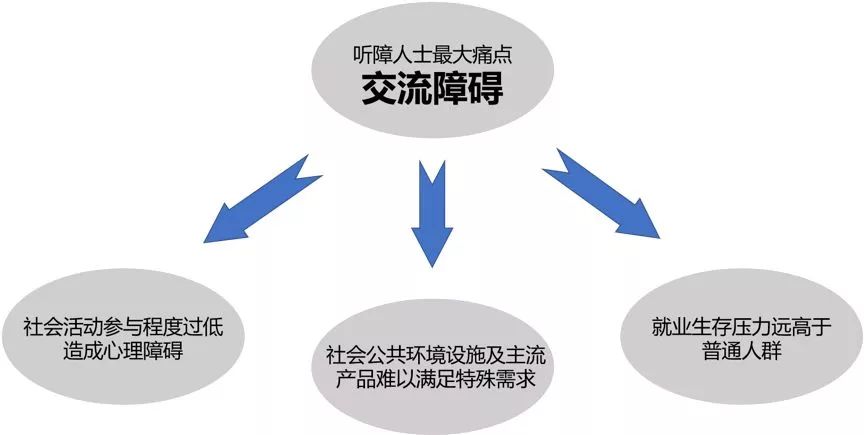
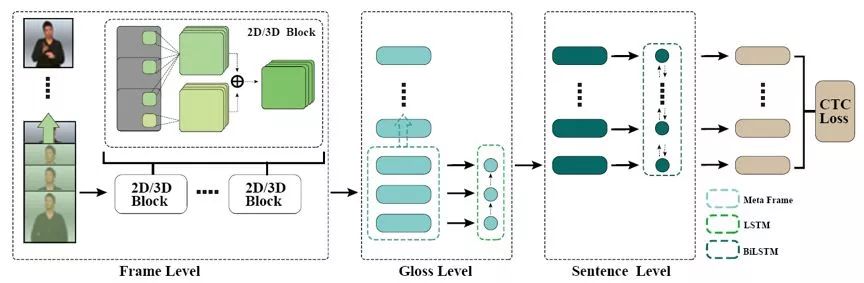
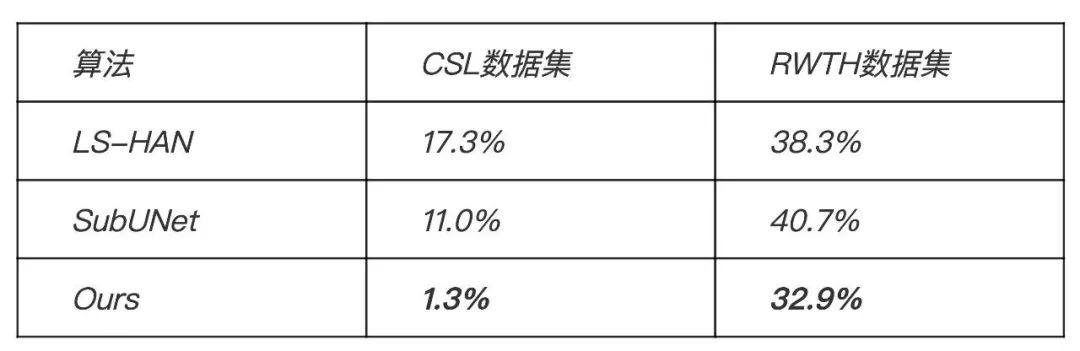
据2017年北京听力协会预估数据,我国听障人群数量约达到7200万。放眼世界,世界卫生组织发布的最新数据显示,全世界有共计约4.66亿人患有残疾性听力损失。尽管听障人群能够凭借手语进行交流,但在机场、民政等公共服务环境中仍然面临沟通障碍等一些亟待解决的问题。 秉承“科技向善”的技术价值观,腾讯一直致力于通过AI等技术手段解决人类面临的社会问题。我们相信,科技能够造福人类,人类应该善用科技,努力去解决自身发展带来的社会问题。作为国内计算机视觉人工智能领域的领先研究团队,腾讯优图实验室近日攻坚AI手语识别并取得突破性进展,自研出一套基于结构化特征学习的端到端手语识别算法,能够识别日常手语并快速运算出结果并把手语翻译成为文字,有望为听障人群正常交流提供更多便利。 目前,腾讯优图实验室已经与深圳市信息无障碍研究会达成合作,并于近日正式发布“优图AI手语翻译机”,探索在机场、高铁、民政等公共服务场所提供手语翻译服务。未来,腾讯优图希望能通过与听障者或手语使用者的深入接触,扩充数据容量,完善数据规范,根据不同的场景优化识别算法,搭建出通过手语与听障人士无障碍沟通的完整系统和平台,用AI消除障碍,做有温度的科技、无差别的科技。 一、潜在需求分析 (一)听障人士数量已达7200万 信息的接收与传递是包括人类在内的任何有机体与世界最为基本的沟通方式,而对于听障人士来说,他们失去了听力这个认识世界最为重要的感知途径。世界卫生组织最新数据显示[1],目前全球约有4.66亿人患有残疾性听力损失,超过全世界人口的5%,估计到2050年将有9亿多人(约十分之一)出现残疾性听力损失。据北京听力协会2017年公开数据,估计中国残疾性听力障碍人士已达7200万[2],相当于北京市常住人口(约2200万,2015年数据)的3倍多,是我国少数民族人口中最多的民族壮族(约1500万,2015年数据)的近5倍,这其中还不包括轻中度听损的人口。 (数据来源:世界卫生组织官网) (数据来源:2017年北京听力协会预估) (二)无障碍普及率有待提升,听障人群需求被忽视 《2017年百城无障碍设施调查体验报告》显示,我国无障碍设施整体普及率仅为40.6%[3],除了普及率较低,还存在部分无障碍设施被占用、维护不到位、设计存在问题等情况。而与其他残障人士不同的是,在现实生活中,听障者除了使用手语交流以外,与普通人几乎没有区别,这也正是听障者容易被忽视的原因之一。目前的公共环境设施、产品设计等往往忽略了听障者的特殊需求。听障者面临的不仅仅是日常交流上的障碍,更多的是沟通障碍所衍生的诸多不便。 (听障人群痛点分析) 《光明日报》的一篇报道曾指出[4],因为沟通障碍,绝大部分的听障者都生活在自己封闭的小世界里,社会活动参与度极低的他们往往会感到孤独。虽然受过教育的听障者也能够使用文字进行交流,但是对于他们来说,手语是更易于使用和接受的交流方式,而我国目前致力于听障者专业服务的人士只有大约一万名,大部分公共服务并没有配备专门的便利设施,这些都是听障者长久以来面临的迫切需求。 科技的进步为大众生活带来诸多便捷,而对于愈发庞大的听障人群,他们的生存状态需要得到社会的更多关注,他们迫切需要前沿科技为他们解决交流障碍带来的诸多不便。 二、手语表达与AI技术结合的行业探索 (一)各研究机构展开探索尝试,技术落地存在诸多因素限制 手语翻译的核心技术是手语识别(SLR)。这个技术就是指通过计算机算法,自动区分手语表达中的各类手势、动作以及这些手势和动作之间的切换,最后将表达的手语翻译成文字。传统的方法通常会针对特定的数据集设计合理的特征,再利用这些特征进行动作和手势的分类。受限于人工的特征设计和数据量大小,这些方法在适应性、泛化性和鲁棒性上都非常有限。 近年来,大数据和深度学习极大推动了人工智能算法的发展,尤其体现在计算机视觉、自然语言处理和音频处理等领域,这助推了AI算法在许多应用和场景中实现落地,许多研究员和工程师也开始尝试运用深度学习和数据驱动的算法来解决SLR的问题。然而不同于大部分的计算机问题,手语特有的地域性、复杂性和多样性,不仅增加了数据采集和清洗的难度和成本,也使得这门技术哪怕在深度学习的帮助下也依然存在很大的挑战,难以被实际应用。 目前,有研究机构或单位针对解决听障人群沟通问题的技术研究,但研究方向多集中在将文字转化成手语方向,而“针对听障人群的手语识别转化成文字”的方向因为技术难度极大,尚鲜有技术方案落地。 (二)腾讯优图自研手语识别算法,推出“优图AI手语翻译机” 腾讯优图结合听障人士手语表达的习惯采集了手语数据,利用前沿的图像序列分析技术自研了一套手语识别算法,推出“优图AI手语翻译机”。AI手语翻译机以普通摄像头作为手语采集装置,依托高性能计算机进行后台运算,能够实时地将手语表达翻译成文字。对于用户而言,不需要携带任何额外装置,只要面对摄像头完成正常的手语表达,就能从翻译机中得到反馈回来的识别结果。 (优图AI手语翻译机界面截图) 三、优图AI手语翻译技术解读 (一)算法优势 相比于此前的手语识别相关的产品和技术方案,我们的手语识别算法主要能够实现以下几点优势: 1. 基于纯RGB图像序列 手语表达极具复杂性,一个手势或者动作幅度的小变化就可能会造成表达意思上很大的不同。因此,之前的很多产品或方法往往需要借助于一些额外的设备,例如使用Kinect摄像机的多种传感器来提前获取手语表达者的肢体关节点信息,又例如在手上携带传感器手套、或配备EMG、IMU传感器的手环来获取手臂和手掌的活动信息。这些额外的设备无形之中增加了使用的门槛,同时也带来了一定的不便利性。 与此不同,我们的翻译机不需要任何额外设备的帮助,用户只需要一个普通的摄像头(如手机摄像头或普通网络摄像头)对手语表达者的表达过程进行拍摄,翻译机就可以完成识别翻译的过程。 2. 支持多样性表达 手语极具地域性和多样性。地域性即指不同地区(如深圳和广州)对同一个词可能存在不同的表达方式,同时由于个人习惯,即便是在同一个标准下,动作的呈现也可能不尽相同。多样性则体现在手语表达中,同一个动作在不同的语境之中可能有着非常不一样的意义,而同一个词在不同的语境中又可以使用不同的动作进行表达。尽管这些情况非常常见,多样性的问题在之前的产品或方法中是没有被考虑进去的。 我们首次将多样性的问题考虑到了算法识别的过程中,支持常见的多样性表达,用户不需要针对翻译机学习某种特定的词与动作之间的映射,根据自己平时的表达习惯进行表达即可。 3. 灵活的整句识别 听障人士进行手语表达往往以句子为单位,表达完一个完整的句子之后才会出现停顿,在一个句子的不同词之间很少会做停顿。然而之前的许多产品或算法实际上是以词为单位进行识别的,需要在词与词之间做出明显的停顿。另外为了能够将语句进行划分,还可能需要设定特定的起始动作和结束动作,在每次表达开始和结束时作为信号语句划分的信号。这限制了使用的灵活性和流畅度。 与此不同,优图AI手语翻译机能够实现整句的识别和翻译,用户表达的时候可以连贯将整个句子表达完。也不需要设定特定的结束或起始动作,而是直接对用户的动作与否进行判断。 (二)实现方法 与听障人士手语表达高度符合的数据集、先进的手语识别算法是翻译机得以实现的有力支撑。 (手语识别算法总体框架图) 1. 更大更全的手语识别数据集 我们通过与社会相关机构和听障人士的接触了解了手语表达的特点,并根据这些特点采集了自己的手语识别数据集。同时对数据进行进一步的分析和归纳,目前,AI手语翻译机的数据集覆盖了近千句日常表达,900个常用词汇,是最大的中文手语识别数据集。 不仅如此,采集数据集还考虑了手语的地域性和多样性表达,包含了不同的表达习惯和速度。这为进一步提升我们算法的泛化能力提供了很好的基础。 2. 更强大的特征提取器 为了能够在手语极具复杂性的表达中充分提起识别所需要的特征信息,我们结合了普通2D卷积网络和3D卷积网络的优势,通过2D卷积网络来提取手语中的手势和身体姿势等静态信息,同时通过3D卷积网络来提取手语中普遍存在的细微而快速的变换动作的动态信息,最后将这两个信息相结合,产生我们最后的特征表达。 静态和动态信息的结合形成了很好的互补,同时避免了信息过早的流失,在我们的实验中对我们识别效果的提升很有帮助。在充分利用了视频中的动、静两种信息之后,我们的算法也得以能够利用单纯的RGB视频图像就达到识别的目的,不需要借助额外的传感器设备。 3. 句子表达中挖掘词级信息 虽然听障人士在进行手语表达的时候是以句子为单位的,但是句子又是由不同的词语组合而成的,因此从语法上来说,词才是手语的最小表达单元。与此同时,一个词语的表达往往不是一个单一的动作和手势,而是一些手势和动作的变换,这个过程有长有短,之间也没有刻意的停顿,因此往往掩盖在了整个句子的表达之中。 为了将这些词语表达的信息挖掘出来,我们的算法在视频帧与最后的输出之间加入了词级信息提取单元,词级信息提取单元利用长短时网络充分考虑特征提取器所提取出的信息,并结合视频中相邻的信息计算出词级的特征表达。这个单元帮助我们的算法能够更好地在句子中找到词语表达的边界,并提升对各种地域性表达的总结能力。 4. 单句切分并充分考虑句中上下文信息 我们的算法在提取词级信息的基础上还会充分将整句中的上下文信息进行综合考虑,然后再输出最后的识别结果。这对识别手语中的多样性表达非常重要,因为同样的动作只有放在上下文的语境中才能最后确定它的意思。 同时,为了减少用户在使用过程中的限制,我们在手语识别之前加入了人脸检测和动作检测两个模块,用人脸检测确定手语表达者的位置,然后用动作检测判断他是否在做手语表达。三个模块协同合作,最后让翻译机能够自适应地找到用户的位置,并连贯识别用户的一系列表达。 (与其他算法在两个公开手语识别数据集上的性能对比,数据显示的是词错率(WER),越低越好) (三)落地条件限制及应用方向 就目前来说,优图AI手语翻译机仍处于实际应用探索阶段。主要受三个问题限制,一是需要高性能计算机,二是复杂环境背景的适应性,三是语料库进一步拓展。 因此,我们将进一步探索在一些公共事务场所如机场、民政等公共服务领域等提供无障碍沟通解决方案,方便听障人日常交流提供便利。 四、意义和愿景 优图AI手语翻译机是腾讯优图基于先进的动作识别和视频分析算法对手语识别技术的一次扩展和优化。我们始终相信,作为AI技术的探索者,解决和优化技术难题是团队应肩负的责任和担当,创造和传播AI的价值和温暖是团队应秉持的使命和信仰。 我们将在未来对我们的AI手语翻译机进行持续的升级和优化,让AI手语翻译机走进听障人士的生活,在日常服务窗口、手语教育等场景中为听障人士带来实实在在的便利。我们希望以手语翻译机为媒介,深入接触听障群体,进一步了解手语和优化我们的数据和识别算法,使我们的翻译机能够覆盖更多的表达和场景。我们更希望我们的AI手语翻译机能够助力手语的普及和规范,增加社会对这个群体的关注度,帮助听障人士更好地融入社会,让他们能够和我们一样,更好地享受和体验技术创新和科技发展所带来的红利。 实际上, 这并不是腾讯在AI+无障碍建设上的首次尝试,腾讯一直在坚持推动“一个都不能少”和“信息无障碍”理念的传播与落地。2018年12月3日,腾讯获得了“联合国教科文组织数字技术增强残疾人权能奖”。 腾讯自 2009 年起在信息无障碍方面率先展开探索,截至目前,旗下QQ、QQ空间、微信、腾讯网、腾讯新闻、应用宝、企鹅FM等大部分产品已针对障碍用户实现专门优化。腾讯旗下各类产品从社交、娱乐、新闻等多维度出发,共同努力,为障碍人士构建友好的信息社会。 感谢深圳市信息无障碍研究会及所有参与此次优图AI手语研究项目的团队和个人。 腾讯优图实验室